-
Mon feedback sur Devoxx 2024 - vendredi
Dernier billet de rétrospective de mes trois jours à Devoxx 2024 : voici le résumé des sessions auxquelles j’ai assisté le vendredi.
-

Mon feedback sur Devoxx 2024 - jeudi
La seconde journée de conférences était assez dense. Elle s’est terminée par des rencontres assez sympa avec des gens que je n’avais pas revu depuis très longtemps. Dans ce second, billet je vous partage les retours des conférences que j’ai suivies : ça pourrait vous donner une idée de curation des talks qui seront disponibles sur Youtube.
-

Mon feedback sur Devoxx 2024 - mercredi
Ça faisait assez longtemps que je n’avais pas participé à une conférence et l’occasion s’est présentée pour moi de participer à l’édition 2024 de Devoxx. Je vais donc revenir dans ce billet sur les différents talks auxquels j’ai choisi d’assister.
-

Participation au forum des métiers
J’ai participé au forum des métiers du collège Lucie Aubrac. J’avais 25 minutes pour intéresser 12 à 20 élèves de 4ème et 3ème au métier de développeur. C’était un petit challenge. Voici mes impressions sur le déroulé de ces cinq sessions successives.
-
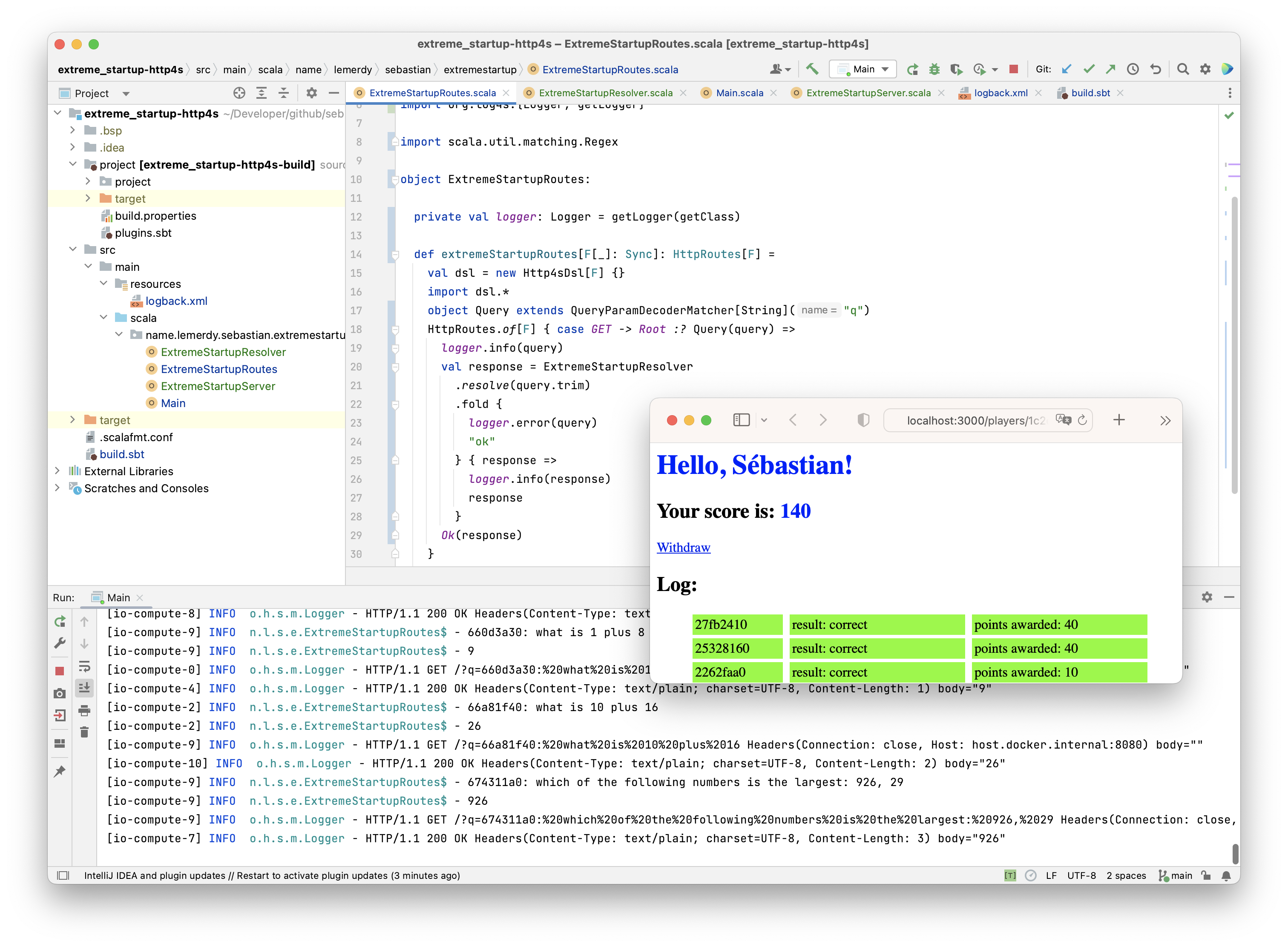
On devrait toujours savoir maîtriser une stack web
Un jour un homme sage m’a dit que tout bon développeur devrait toujours avoir un stack web favorite et maîtrisée du bout des doigts. C’était il y a très longtemps. Cela dit, je pense que ce conseil est encore et toujours vrai en 2023. N’importe quel produit aujourd’hui s’appuie sur le protocole http et sur des apis rest clientes et/ou serveur. Il est temps pour moi de choisir à nouveau cette stack.
- •
- 1
- 2